LoL: Graph Networks for Champion Recommendations
Why are Graph Networks useful?
Let us imagine you worked for Riot Games. Your first task is to design a way of generating Champion (playable characters) recommendations in their game, League of Legends. How would you approach the problem?
The standard approach is to label each Champion with key attributes, then connect them based on these common attributes. We can use this to assume that Player 1 who enjoys Champion A will also enjoy the similar Champion B.
Example: Zed is a Mid lane Assassin who uses Melee attacks and has a high mobility kit. Talon shares these attributes and therefore if Player 1 enjoys Zed, we can assume they’ll likely enjoy Talon.
However, by instead using a Graph Network we can attack the problem in reverse: If we already know on average players who enjoy Champion A enjoy Champion B, those who currently only play Champion A will likely enjoy Champion B — regardless of what attributes they share.
Example: Players who play a lot of Zed, also play a lot of Talon. If Player 1 only plays Zed, they will likely enjoy Talon too. We can assume there’s similarities between the two Champions — we just don’t need to define what they are.
Context
You can read more about Graphs here.
“Node” = a particular point in the Graph, in this context a “Node” is a Champion
“Edge” = The connection between two Nodes (Champions). If there is no edge, the two Champions are not connected. Sometimes used with a weighting (also referred to as Distance between Nodes).
Data Gathering
With any Data Science problem, the first step is to gather the data. To start this, we require a random selection of Summoner names. Luckily, this is all easily accessible through the Riot API tool.
We first create a list of regions and divisions. For this, I have used 3 Regions (EUW, NA and KR) and the following Divisions: Diamond, Platinum, Gold, Silver and Bronze(Ratio 1:2:4:4:2). The loop below can then be used to create a list of c. 8,000 Summoner IDs at random.

Loop code used to create a randomised list of Summoner IDs
Once we have these IDs, we can again use the Riot API to loop through each Summoner to find their Top 5 played Champions. The table below the code shows for 5 random players, which 5 Champions they play most often (shown as a Champion ID).

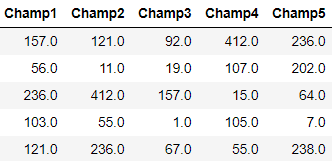
Each players Top 5 Champions (using Champion ID)
By aggregating this dataset we can answer the following question for each Champion: When they appear in the Top 5 list for a Player, which Champions are also most commonly in that same list?
This creates the following table:
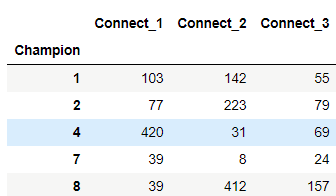
We can see for Champion 1 (Annie), the most common connection is Champion 103 (Ahri). In the simplest of terms: for all 8,000 players, those who play Annie regularly will also play Ahri regularly more than any other Champion.
With another simple loop, we can transform this table to a matrix — where Champion ID 1 (on the Y axis) will be connected to Champion 103, 142 and 55 on the X axis. Then again, transposing this in the same way X to Y. This will be replicated across all Champions. Below the code is an illustrative example (not real data) of the final matrix. Champ IDs appear on the X and Y axis, where 1 determines a connection between two champions, 0 indicates no connection.
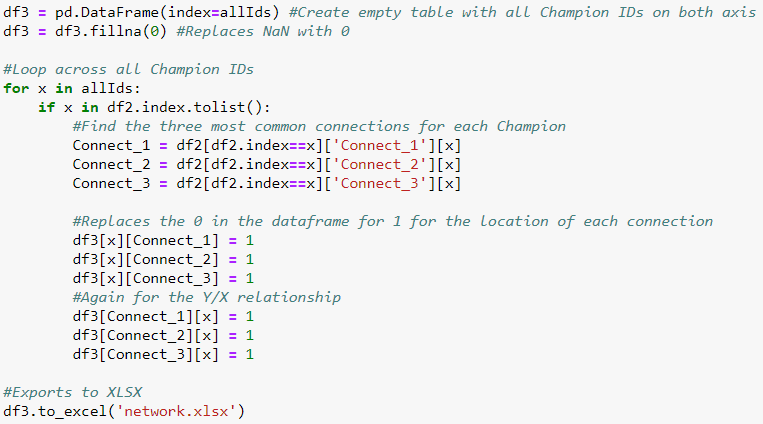
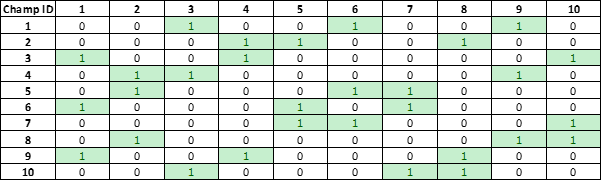
The data gathering is now complete.
Graph Network
The next step is to create the Graph Network, for this I will be using NetworkX to create the Graph based on the matrix that we saved previously. We then visualise it in more detail using Bokeh. The full code is below:
This creates the following graph:
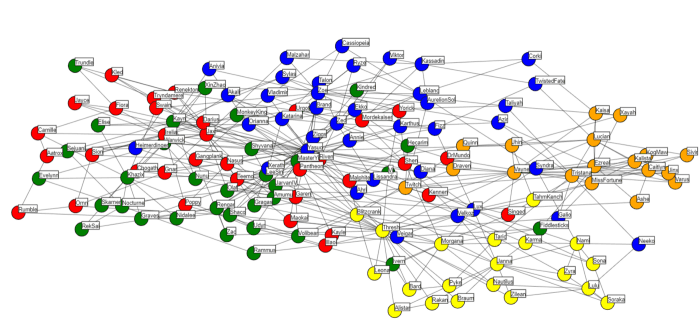
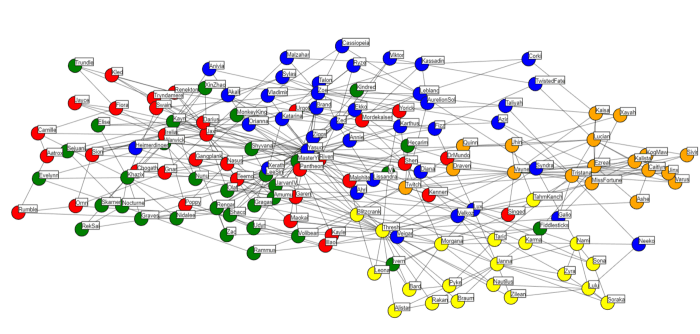
The nodes have been coloured by lane (Yellow: Support, Orange: ADC, Blue: Mid, Green: Jungle, Red: Top). From this we could derive some interesting findings, such as Thresh/Blitzcrank tends to be the Support played by non-Support players (as it’s closest to the other lanes groupings), whilst Soraka tends to be the Champion of choice for Support mains (as it’s deepest into the Support grouping). This logic can be applied throughout, check out the interactive graph and come to your own conclusions!
But does it help with recommendations? The answer is dependent. Yes, if you are looking for a Champion in your preferred lane, no otherwise. Why is this?
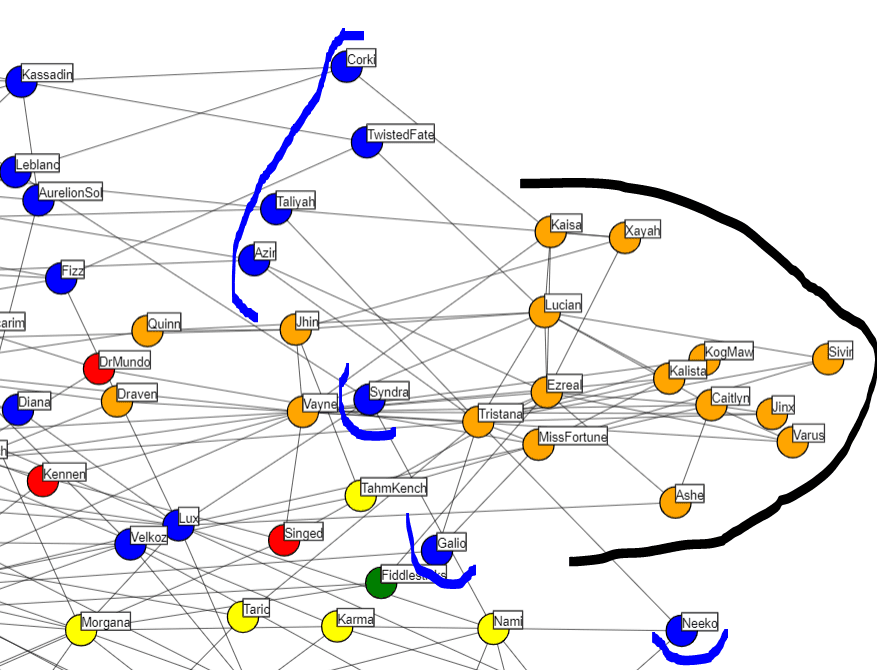
Let’s say you were an ADC main, you can assume your Top 3 Champions will be grouped somewhere around the orange section that is highlighted in black. If we used this Graph to recommend a Champion, it’s pretty much certain that it will only recommend a small selection of Mid laners that are closest to the ADC grouping (Marked in blue). This isn’t a tailored recommendation. Rather than taking your particular playstyle from your unique ADC Champions, it simply defaults you to a generic ADC player and assumes you like exactly the same as all other ADCs.
To improve this, we need to return to data gathering
Data Gathering 2: Return of the API
This time around, we are approaching the task differently. Instead of finding each players Top 5 Champions, we will find each players Top 3 Champions per lane. This means that for each Champion, we will also have common connections to every lane.
The loop code is rather long so I won’t include it here. In the end, we are left with a matrix that takes each Champion, and connects it to the top 3 Champions in each lane (15 connections in total). As well as this, these Edges will now also be weighted by their average Champion mastery as a percentage of that lane.
Example: If you are an ADC main who plays Thresh (80k mastery), Blitzcrank (10k mastery) and Pyke (10k mastery) in Support. Then Thresh will be given 80%, Blitz 10% and Pyke 10%.
This is inversed and calculated as: Edge A to B Weight = 1 — (Champ B Mastery Points / Total Champ Mastery Points). This way, the higher the percentage of the players mastery in a lane is on the champion — the lower the edge weighting (also known as the distance between nodes).
Graph Network 2: Electric Boogaloo
Now we have a new approach to the Graph Network, we can re-create the graph using the same code.
This is far more complex than the previous. There are a multitude of connections between nodes, and the weighting determines the distance between them. Although not visually pleasing, it now should offer a stronger recommendation.
Recommendation Engine
The final part is to create the engine. For this, we return to the Riot API. By inserting our own Summoner name and Region we can call a list of our most played Champions. We take our Mains and use Dijkstra’s Algorithm to determine the length from our Champions to every other Champion. We remove any Champions we already play regularly, group them by lane and voila —we will find the closest Champions to the ones we already play.
Example: I am an AP Mid main, mostly playing Battle Mages such as Vel’Koz and Lux. My Top lane recommendation was Teemo, my Mid lane was Cassiopeia and my Support was Morgana. This makes sense, we would have probably arrived here using the simple approach outlined at the beginning of this article. However, for ADC I was recommended Jhin — and this I cannot explain. I have never played Jhin, but those who share my love of Battle Mages also seem to enjoy Jhin when they play ADC. To quote the Virtuoso himself, my audience awaits!